ワダです。今回は、ID値の生成方法について試したことを書いてみます。
主キーについて
(詳しい方はスルーしてください)
主キー=行レコードの一意性が識別できる列の組み合わせ。
DBMSのテーブルに登録するレコードを一意に絞るために、テーブルには「主キー」が必要です。
主キーの生成方法
主キーの設定方法には、以下のような種類があります。テーブルに入れたいデータの用途などによって使い分けます。
- 1ナチュラルキー(自然キー)
- 1-1単純キー
例)都道府県名 -
1-2複合キー
例)都道府県名+市町村名
- 1-1単純キー
-
2サロゲートキー(代替キー)
※連番やランダムな値などの一意の値を格納するカラムを用意し、自然キーの代わりに主キーとするもの。- ★2-1 単純代替キー★
例)「ID」列 -
2-2 複合代替キー
例)ID列 + 登録日時
- ★2-1 単純代替キー★
ナチュラルキーを使ったテーブルは、結合時に結合条件が多くSQLが複雑になりがちなため、
ナチュラルキーよりもサロゲートキーを用いる方が仕様変更に強かったり、SQLのバグが少ないなど、開発時には有利な場面が多いと思います。
今回試した方法
今回は、上記の「★2-1 単純代替キー」の場合の、ID列に入れる一意な値の生成を試してみました。
試した方法は以下の3つです。
– ①採番テーブルを使う
– ②DBMSのシーケンスを利用する
– ③プログラム内で生成する。(UUID等)
①採番テーブルを使う
採番テーブル「NUMBERING」
|
1
2
3
4
|
--採番テーブル
CREATE TABLE [sch1].[NUMBERING](
[ITEM_NAME] [nvarchar](50) NOT NULL,--項目名
[LAST_NO] int )--最終払い出し番号
|
以下は採番した番号を入れていく方のテーブル「EMPLOYEE」。
|
1
2
3
4
5
6
7
|
--従業員テーブル
CREATE TABLE [sch1].[EMPLOYEE](
[EMPLOYEE_ID] [nvarchar](10) NOT NULL,
[NAME] [nvarchar](50) NOT NULL,
[INSERT_DATE] [date] NULL
PRIMARY KEY(EMPLOYEE_ID)
)
|
・使用例
以下は実行前の採番テーブルの状態。
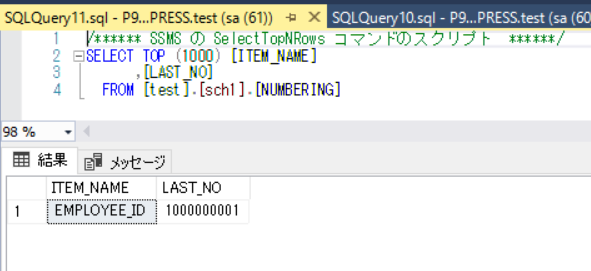
以下のように、トランザクションの中で採番テーブルを更新(1000000001→1000000002)し、従業員テーブルにINSERTする。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
BEGIN TRAN
--新規の従業員を登録する前に、採番テーブルを更新する
SELECT * FROM sch1.NUMBERING WITH(XLOCK,ROWLOCK)WHERE ITEM_NAME='EMPLOYEE_ID'; --行ロック
UPDATE sch1.NUMBERING SET LAST_NO = LAST_NO + 1 WHERE ITEM_NAME='EMPLOYEE_ID';--最終払い出し番号の更新
--新規の従業員を登録する。
INSERT INTO sch1.EMPLOYEE(
EMPLOYEE_ID,
NAME,
INSERT_DATE)
VALUES(
(SELECT LAST_NO FROM sch1.NUMBERING WHERE ITEM_NAME='EMPLOYEE_ID') ,
'従業員名2',
CONVERT(VARCHAR, getdate(), 111)
);
COMMIT TRAN
|
実行結果
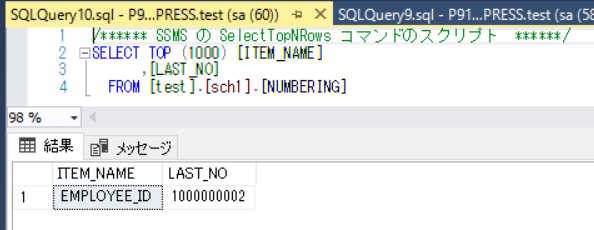
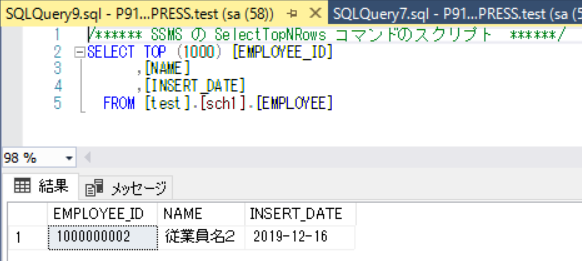
採番テーブルのメリット・デメリット
メリット :どのDBMSでも同じ方法で使える方法である。
デメリット:ほかの方法と比較すると性能があまりよろしくない。採番テーブルを複数人が同時に更新しないよう
トランザクションの期間に気を付ける必要がある。
②DBMSのシーケンスを利用する
シーケンス「EMPLOYEE_SEQ」を作成。10桁のEMPLOYEE_IDに対応するように開始値を「1000000001」に設定。
|
1
2
3
4
|
--従業員IDシーケンス
CREATE SEQUENCE [sch1].EMPLOYEE_SEQ
START WITH 1000000001
INCREMENT BY 1;
|
・シーケンス値を入れるテーブル「EMPLOYEE」は①と同じ。
・使用例
例)新規従業員を登録する。
「EMPLOYEE_SEQ」を利用してEMPLOYEE_IDを取得し、「EMPLOYEE」テーブルに登録する。
|
1
2
3
4
5
6
7
8
9
|
INSERT INTO sch1.EMPLOYEE(
EMPLOYEE_ID,
NAME,
INSERT_DATE)
VALUES(
NEXT VALUE FOR sch1.EMPLOYEE_SEQ,
'従業員名3',
CONVERT(VARCHAR, getdate(), 111)
);
|
実行結果
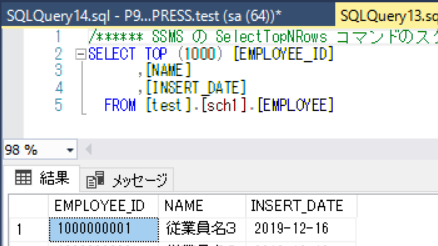
シーケンスのメリット・デメリット
メリット :設計が楽。実装も楽♪。
デメリット:シーケンスは、DBMSごとに作成方法が異なる。また対応していないDBMSもある(らしいです)。
③プログラム内でID値を生成する
JavaのUUIDを利用してランダムな値を生成する方法を試しました。
SQLServerのテーブルは、UUIDを格納するカラムを「UNIQUEIDENTIFIER」型で作成します。
テーブル「UUIDSample」
|
1
2
3
4
5
|
CREATE TABLE [sch1].[UUIDSample](
[UUID] [uniqueidentifier] NOT NULL,--「UNIQUEIDENTIFIER」型で作成
[INSERT_DATE] [date] NULL,
PRIMARY KEY(UUID)
)
|
プログラム
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
|
//UUIDSample.java
import java.sql.*;
import java.lang.Object;
import java.util.UUID;
class UUIDSample {
public static void main(String[] args) {
try {
// データベースとの接続
Connection con =
DriverManager.getConnection ("jdbc:sqlserver://localhost\\SQLEXPRESS;database=test","test01","test01");
//UUID取得
UUID uuid = UUID.randomUUID();
String uuidStr = uuid.toString();
System.out.println(uuid.toString());
StringBuilder sql1 = new StringBuilder();
sql1.append("INSERT INTO sch1.UUIDSample(");
sql1.append(" UUID");
sql1.append(" ,INSERT_DATE");
sql1.append(")VALUES(");
sql1.append("'"+uuidStr+"'");
sql1.append(",CONVERT(VARCHAR, getdate(), 111)");
sql1.append(")");
//PreparedStatement stmt = con.prepareStatement(sql1.toString());
Statement stmt = con.createStatement();
int num = stmt.executeUpdate(sql1.toString());
System.out.println(num + "行INSERTしました");
// データベースのクローズ
con.close();
} catch (Exception e) {
System.out.println("Exception発生");
e.printStackTrace ();
}
}
}
|
実行
|
1
|
java -cp .;sqljdbc42.jar UUIDSample
|
実行結果
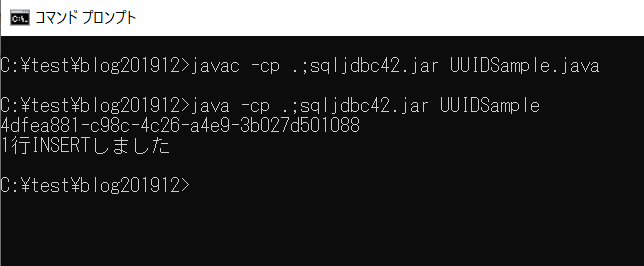
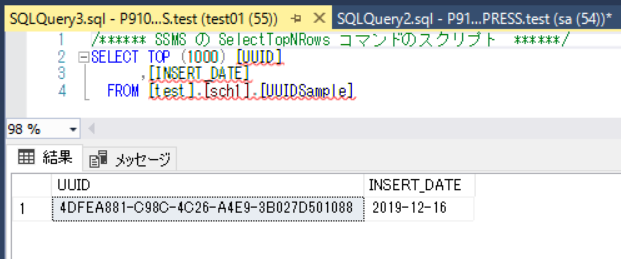
プログラム内でID値を生成するメリット・デメリット
メリット :採番をRDBMSに任せずに行うことができる。乱数を使用するため、重複の可能性は限りなく小さい。
デメリット:連番としては使えない。そのためこの列でのソートはできない。
ソートしたい場合は登録日時等との複合代替キーにするなど工夫が必要。
■あとがき
・個人的には、②のシーケンスに任せられる状況なら、それがベストな気がします。
・ただし社員IDのようにコード体系がきっちりしている状況なら、①の採番テーブルが望ましいと思います。
・(いつものことながら)書く内容が基本的なことにとどまっていますが、、どこかで役立てられれば幸いです。
■環境について
・OS
Windows10 Pro ビルド番号 1903
・DBMS
SQLServer 2012
・SQL Server Management Studio
バージョン4.1.4.21
ビルドMAIN-21.21
・Java
java version “1.8.0_221”
参考サイト
・【データベース設計】採番について
・データベースのPRIMARY KEYを自動採番せずにアプリケーション側で生成する
・ソート可能なUUID互換のulidが便利そう
(こちらは今回は試していませんが、ミリ秒単位で時系列ソートができるライブラリがあるようです。)
https://qiita.com/kai_kou/items/b4ac2d316920e08ac75a
以上です。ありがとうございました。