ワダです。以前サロゲートペア文字を扱う場合にDB設計で悩んだことがありまして、備忘のためにいつかまとめておきたいと思っていました。
■サロゲートペア文字とは
Unicodeで1文字を4バイトで表現する文字のこと
通常Unicode(※)では1文字あたり2バイトで表現しますが、近年では2バイトではすべての文字を表現するには足りなくなったために、
一部の文字については1文字を「上位サロゲート」+「下位サロゲート」の4バイトで表現するようになりました。
このような文字のことをサロゲートペア文字といいます。
※Unicodeの文字体系には「UTF-8」「UTF-16」「UTF-32」などの種類がありますが、ここではWindows標準の「UTF-16」を指します。
詳しい説明は以下を参照してください。
参考:Wikipedia Unicode -サロゲートペア
https://ja.wikipedia.org/wiki/Unicode#サロゲートペア
参考:サロゲートペア文字入門
https://codezine.jp/article/detail/1592
例)以下のような文字があります。
- ?(ほっけ)
- ?(しかる) ※「叱」とは別の文字)
- ?
など
■サロゲートペア文字を含むカラムの設計 ~Oracleの場合~
まずOracleでサロゲートペア文字を扱う場合の設計について考えます。
【前提】
今回使用するDBのデータベースキャラクタセットは以下の通り。
NLS_CHARACTERSET ・・・AL32UTF8
NLS_NCHAR_CHARACTERS・・・AL16UTF16
文字列を扱うデータ型は「CHAR」「NCHAR」「VARCHAR2」「NVARCHAR2」とありますが、
今回は可変長の「VARCHAR2」「NVARCHAR2」を取り上げます。
VARCHAR2
初めにVARCHAR2型のカラムを持つ以下のテーブル「TABLE1」に、サロゲートペア文字を含むデータをINSERTします。
「VARCHAR2(10)」のカラムには10バイトまでのデータが格納できます。
|
1
2
3
4
|
--VARCHAR2用のテーブル
CREATE TABLE TABLE1 (
COL_A VARCHAR2 (10) --10バイトまで入る
)
|
結果
↓↓↓
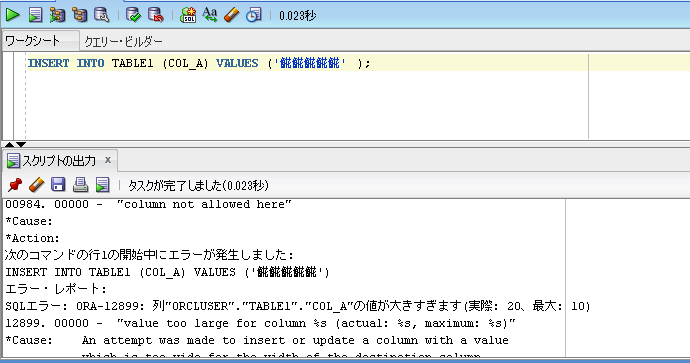
“TABLE1”.”COL_A”の値が大きすぎます(実際: 20、最大: 10)というエラーが出ます。
「VARCHAR2(10)」には10バイトしか入らないため、桁数オーバーになっています。
サロゲートペア文字が入る可能性のあるカラムについては、一律1文字最大4バイトと想定してカラム長を定義すれば良いのでしょうか?
可変長とはいえ、容量見積もりの観点では無駄が多いような気がします・・・。
NVARCHAR2
次に、NVARCHAR2のカラムにINSERTしてみます。
「NVARCHAR2(10)」のカラムには1文字2バイトのUnicode文字が10文字まで格納できます。
|
1
2
3
4
|
--NVARCHAR2のテーブル
CREATE TABLE TABLE2(
COL_B NVARCHAR2 (10)
)
|
結果
↓↓↓
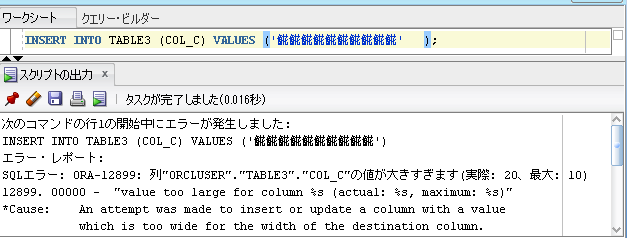
?は4バイトなので、10文字の半分=5文字までしか入りませんでした。
半分の5文字にした結果
↓↓↓
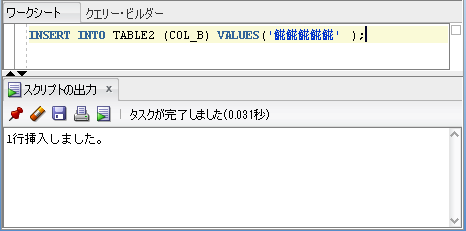
入りました。
設計する際はNVARCHAR2の場合はサロゲートペア文字が入ってくる可能性を考えて想定の文字数×2でカラム長を定義すると良さそうです。
「列長セマンティクス」について
Oracleの場合「列長セマンティクス」という概念があります。
これによって、VARCHAR2では列の長さをバイト単位に指定するか文字単位に指定するかを選択できます。
デフォルトはバイト単位。これを文字単位に指定する場合は「CHAR」を指定します。
参考:列長セマンティクスとUnicode
https://docs.oracle.com/cd/E57425_01/121/REPLN/repunicode.htm
以下の「TABLE3」ではカラム長をバイト数ではなく文字数で定義しているため、
1バイトの文字だろうと4バイトのサロゲートペア文字だろうと
定義した文字数分格納できます。
|
1
2
3
4
|
--VARCHAR2 文字数セマンティクス
CREATE TABLE TABLE3(
COL_C VARCHAR2 (10 CHAR) --列の長さを文字単位に指定
)
|
INSERT結果
↓↓↓
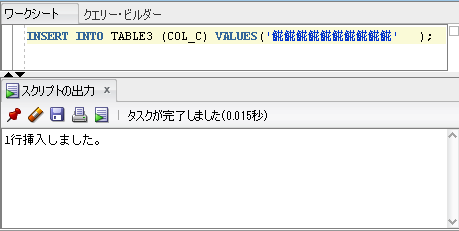
カラム「COL_B」にサロゲートペア文字を10文字格納できました!
まとめ
VARCHAR2とNVARCHAR2 どちらで定義するか迷ったら、以下のことを基準に設計を考えると良さそうです。
VARCHAR2
- カラム長はバイト数(デフォルト)または文字数(CHARをつける)で定義可能。
- データ量の幅が大きく(1文字につき1バイト~4バイト)、見積もりが難しい
- 半角数字、アルファベットなど1バイトでの文字を多く格納する場合はVARCHAR2の方がコンパクト。
- サロゲートペア文字が含まれる場合は文字数セマンティクスで定義すると、格納時にサロゲートペア文字を意識しなくて済む。
NVARCHAR2
- カラム長は文字数で定義する。サロゲートペア文字を除き全て2バイト。サロゲートペア文字は2文字とカウントされる。
- 全角、ひらがな等日本語を多く格納する場合はNVARCHAR2。
- サロゲートペア文字を扱わない場合は、データ量の見積もりがVARCHAR2より容易。
■サロゲートペア文字を含むカラムの設計 ~SQLServerの場合~
次にSQLServerについて考えます。
【前提】
今回使用するSQLServerのデフォルトのサーバーの照合順序は「Japanese_CI_AS」(バージョン90)。
データベースに格納される文字は、照合順序「Japanese_CI_AS」に対応するコードページ「932(=Shift_JIS)」。
※SQLServerのデータベースキャラクタセットはインストール時の照合順序で決まります(前々回の自分の記事に確か書いたような・・。)
Oracle使い向け OracleとSQLServerの違い
文字列を扱うデータ型は「CHAR」「NCHAR」「VARCHAR」「NVARCHAR」などがありますが、
Oracleと同様に、今回は可変長である「VARCHAR」「NVARCHAR」を取り上げることにします。
VARCHAR
まず、下記のテーブルにサロゲートペア文字をINSERTしてみます。
Oracleの場合と同じく1文字が4バイトのサロゲートペア文字が含まれているので桁数オーバーでエラー・・・??
|
1
2
3
4
|
--TABLE1 varchar
CREATE TABLE TABLE1(
COL_A [varchar](10) NOT NULL
) ON [PRIMARY]
|
INSERT実行結果
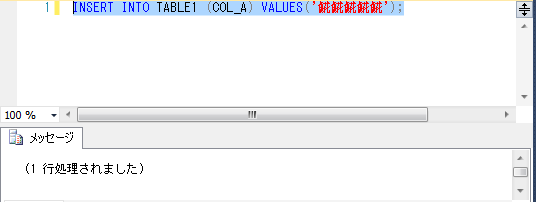
入りました(意外でした・・)。
ただし、SELECTしてみると、文字化けしています。(3レコード目)
SELECT結果
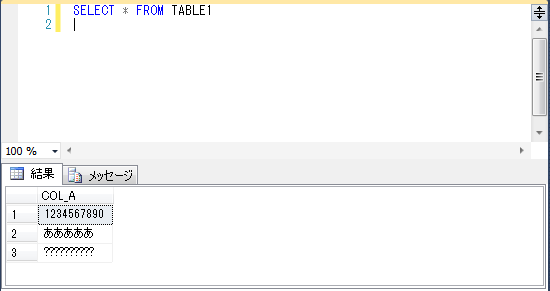
SQLServerはデフォルトのコードページ(cp932)でエンコードするため、存在しない文字を無理やり格納して文字化けしているようです。
NVARCHAR
次に、NVARCHAR型のカラムにINSERTします。
|
1
2
3
4
|
--TABLE2 nvarcharで定義
CREATE TABLE TABLE2(
COL_B [nvarchar](10) NULL
) ON [PRIMARY]
|
結果
↓↓↓
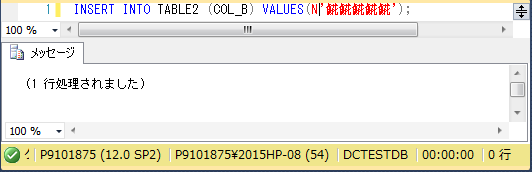
入りました。
ただし、INSERT時に文字列に「Nプレフィックス」をつけずにINSERTすると、下記のSELECT結果1レコード目のように文字化けします。
サロゲートペア文字に関わらず、Unicodeとして扱うデータにNプレフィックスをつけない場合、
OracleのVARCHAR2と同じくSQLServerはデフォルトのコードページ(cp932)でエンコードするため、
文字セットに存在しない文字は表現できず文字化けします。
SELECT結果(文字化けしている)

参考:NVARCHAR/NCHAR データ型の列に格納されるデータが?になる
https://blogs.msdn.microsoft.com/jpsql/2012/05/21/nvarcharnchar/
まとめ
- デフォルトでインストールした場合コードページがcp932(Shift-JIS)なのでVARCHARではサロゲートペア文字を扱えない
- サロゲートペア文字を扱う場合、データ型は「NVARCHAR」一択。
- VARCHARのカラム長はバイト数で定義する(Oracleと異なり、セマンティクスの概念はない)
終わりに
ここまで書いておいてなんですが、最近のDBMSではカラム最大長を指定しなくてもDBMSが自動的にうまくやってくれるようです。(今回は試していませんが)
実際に、業務でアプリ側とDB側でサイズを合わせることに苦労したことが多々あるので、指定なしでいいならありがたい話です。
けれども、現場のルールで最大長を指定しなければいけないケースは少なからずあると思いますので、ここで書いたことが役に立つがあるかもしれません。
今回は以上です。ありがとうございました。